

How Does it Work?
The system is comprised of four subsystems:
-
The Web App for controlling the robot's actions
-
Navigation for navigating to the bookshelves and back to a desk or pick-up point
-
Vision subsystem for finding and identifying the right books
-
The arm which performs the critical action of picking the book up off the shelf
Read about all the subsystems below.


Web App and Networking
Click on the images to enlarge them

Log in page
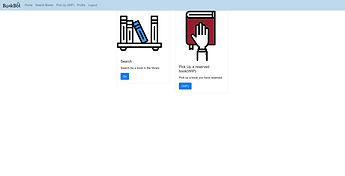
Home page
.png)
Search results page
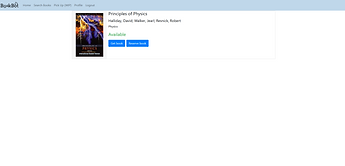.png)
Book ordering page
Web App
The web app is the first point of contact between our system and the user. The design is focused on simplicity in order to be accessible to the wide variety in technical experience that one might find in people visiting a library.
The main pages, displayed on the left, are the login page, the homepage which offers the option to search for a book or requesting the robot to fetch an already reserved book, and the search result page. From the search result page, the user types in a search term and the system will find books that closest match the query. This is achieved by tokenising each word and calculating the Levenshtein distance between the query and the word and returning only books that are close enough to the query
The web app was built using Flask for the back-end and Bootstrap for the front-end. During development we just hosted the web app locally on a DICE machine in the lab, but in practice we would use a more reliable web server such as NGINX or Apache.
Networking
The web server machine acts as a central control point for the system. Each subsystem is initiated and monitored by the web server to ensure that everything is working as intended. If something goes wrong, the web server would detects this and notify the user. For example, if BookBot fails to find the book the user requested, the user is presented with a relevant message which also gives them the option to contact a librarian for assistance.
We used the standard Python implementation of network sockets to achieve the communication we require. Each subsystem acts as a client and a server, since they need to be listening for responses but also need to send requests. For example, the navigation subsystem is always listening for a request from the web server, so that it knows when and where it needs to move, but it also needs to send confirmation messages back to the web server so it can initiate the next subsystem.
We chose this model because this means that in the future we would be able to implement a feature in the web app to give dynamic updates to the user while the system is in operation. It also means all the network configuration only needs to be done on the web app and nowhere else. In addition, this modular architecture, of having self-contained subsystems communicate over the network has made it easier to build and maintain the system.
Navigation
The navigation system navigates the robot to the right bookshelf and back to the user's desk or a designated pick-up point after successfully picking up the book. BookBot’s navigation which runs on the Raspberry Pi 3 relies on a pre-computed map and LiDAR for localisation.
Setting the initial position and sending goals
To communicate navigation data to BookBot's Navigation Stack we used rospy to create navigation ROS nodes with Python. There are two different publishers:
-
One for setting the initial position to align the LiDAR scan with the map. It is used only when BookBot boots.
-
One for sending goal coordinates which BookBot will navigate to. The goal coordinates are received from the web app's request to the navigation socket, as described. This publisher is used when we need BookBot to move to the bookshelf to pick up the book or go to the user's desk or the pick-up point. After sending the goal coordinates, BookBot's navigation system will plan a route.
Planning the route
Since we are using the ROBOTIS navigation library, BookBot will plan the routes using the A* search algorithm. The algorithm's heuristic takes into account distance as well as how close the robot gets to nearby walls. It will favour routes which are shorter and further away from walls or other fixed obstacles. The first diagram on the right shows an example of such a path from point A to point B. If the planned route is blocked, BookBot automatically creates a new route plan.
Checking the goal status
The goal status of the current goal must be checked in two situations. One is before we notify the web application that BookBot has reached the bookshelf. The other one is before sending a new goal.
For checking when a goal has been reached, we use the /move_base/status ROS topic to check the status of a navigation route. In order to avoid race conditions, we use both the status and the unique goal_id to verify that the robot has reached its current goal.
Optimisation by tuning
The navigation process is optimised by the tuning of the Navigation Stack parameters. For example, we are able to provide accurate robot size and shape by specifying its footprint (one of the parameters). Before that, BookBot wasn’t aware of the arm and the container at the back of it which led to collisions sometimes. The second diagram on the right shows the footprint we have defined.

Route planning from Point A to Point B

The footprint of BookBot
Click on the images to enlarge them

Vision
Click on the images to enlarge them

The webcam on the arm

Steps in extracting the labels from the image

Book spine tracking in action

Threads during tracking and alignment
We use computer vision to detect and read the labels which are already present on library books and position the robot to grab the right book. This subsystem runs on the Raspberry Pi 4.
Searching for the book
The robot has two cameras, one Raspberry Pi camera module on the side of its body for lower shelves and one webcam on top of the arm for upper shelves. Both cameras are connected to the Raspberry Pi 4.
Once the robot has navigated to the shelf, it starts searching for the book. This is done by taking a picture with the appropriate camera, identifying the books in the picture. If not found, the robot drives forward and tries again on a new set of books.
Finding the labels in the image
When a picture is taken, the labels should be isolated to read the text. The GIF on the left shows the steps. The picture is first binarised (converted into only extreme black or white) by splitting the image in vertical sections and binarising each one independently to make the algorithm robust to illumination variations and slight differences between the colour of the labels. The resulting binary image is eroded to remove small bright regions, such as white text on the books’ spines. The labels will still be identifiable from the binary image since they are relatively large white regions.
Only the part of the image which contains the labels is needed. The image is cropped to the horizontal part of the image where the number of white pixels per row peaks. This reduced the number of false labels that we might find in other parts of the image and improved the detection of labels on bright books where there is little contrast between the white label and the book spine's colour (For example the 3rd book from the right in the GIF).
Python’s OpenCV library is used to group together all continuous white regions in the cropped image and a rectangle is fitted around each region to represent the position of the label. We only keep rectangles which have size that is close to the one that's expected for a label.
Reading the label text
Once the labels in the image have been found, each label needs to be paired with the correct book title. We use Tesseract for Optical Character Recognition (OCR) as it is considered the most accurate open-source OCR engine. Each label image is in greyscale, binarized, scaled up, dilated, padded with a white border and Gaussian blurring is applied to improve the performance of OCR. Each label text is read in a separate thread to improve performance.
The Levenshtein distance is used to calculate the similarity between the detected label text and the label code of all the books in the target shelf (provided by the web app’s request). The closest match is the identity of the book.
Tracking the label and adjusting the position
The label is tracked in a live video feed from the camera facing the books using OpenCV’s implementation of Discriminative Correlation Filter with Channel and Spatial Reliability (see Evaluation). As the label is tracked, the positions of the vertical boundaries of the book spine are detected around it, using Canny Edge detection followed by Hough Line Transform. This detects all vertical or almost vertical lines in the image and then we select the lines closest to either side of the label. This allows us to track the left and right boundaries of the book spine.
Next, the robot’s position is adjusted until the target book is located in the centre of the frame, i.e. the lens of the camera is directly in front of the target book. The robot's speed is determined by the distance of the book spine from the centre of the frame, moving slower when the spine is closer to the centre to allow more precision as the robot approaches its target position.
The diagram on the left shows the threads used to improve performance. The main thread retrieves the most recent frame from the camera video stream thread and uses it for label tracking, the camera video stream thread continuously polls the camera for new frames and the ROS message publishing thread publishes ROS messages to adjust the robot's speed when aligning with a book.

The Arm
The main job of BB's arm is to retrieve a desired book from a shelf. This book grabbing system runs remotely on the Raspberry Pi 3.
Hardware
For this version of BB, we are using the PincherX 100 robotic arm. This arm is made up of 5 dynamixel motors, that can be moved by publishing each motor's coordinates. It is important to note that this arm is not physically capable of lifting real books, so a real product would require far stronger hardware (which of course was not available within the capacity of this course). For this reason, the testing of our product was done only using prototype books which we designed to meet the capabilities of the hardware. Should the arm be upgraded to a stronger model, however, our method would work with real books.
The Claw
In order to solve the problem of retrieving a book from a tightly packed shelf, we designed a custom 3D printed claw for the arm. This claw is based on the design of the original gripper which came with the PincherX 100 arm. However, we modified this design by adding a sliding mechanism, which allows for the gripper to insert itself into the small spaces surrounding the target book, easily clasp and retrieve it.
The gripper also features tapered rubber pads, improving the overall grip and ensuring the target book does not slip out.
Controlling the Arm
When programming the arm, we chose to use the Open Manipulator with Turtlebot Bot 3 SDK from ROBOTIS, as it not only does it allow for smooth and accurate movements, but also the options to change the arm's dynamixel velocities, read the current position of each of the joints, and much more.
Checking for a Successful Grab
In order to ensure that BB has been able to physically clutch a book, we make use of the bot’s effort data, which is read from the arm’s dynamixels, to tell us how much 'effort' is being exerted on each individual motor. Through carefully testing various values, we have been able to establish what the different effort thresholds are, allowing us to understand what the arm is experiencing while running the script.
Retrieving the Book
After navigating to the bookshelf, finding the book and positioning itself in front of it through vision, BB is now ready to grab the book.
We begin by positioning the arm upright , with the gripper fully open and facing the book. It then slowly reaches in until the tips of the claw's sliders touch the books, indicating a change in the effort data for several of the motors. The goal here is to get the sliders to fit onto either side of the target book, in the gaps between the neighbouring books. So, we begin to slowly close the gripper a little bit, while gently pushing the arm forward. We do this until the sliders manage to match the size of the target book. At this point we see an increase in the wrist motor's effort, which indicates that the sliders have successfully managed to insert itself onto either side of the book (thus being a successful grab).
Then, it is simply a case of gently opening the gripper to slightly push out the surrounding books, before closing it again and pulling out the target to place in BB's storage compartment on its back.
In the current state of our software, BB is only able to retrieve a book from one level of the book shelf. However, had we had more time, we would have been able to very easily implement this exact same method to work for the lower shelf.
Why this Works
Prior to using effort data, we were relying purely on BB's position being exact when initiating the book grabbing script. By reading the effort data and using it as feedback to our program, we were able to eliminate this bottleneck and allow for a margin of error in the initial position, when the book grabbing system is called from the web app. Furthermore, by creating a specified threshold for the effort, we ensure that no extra strain is put on the hardware, which would otherwise cause it to crash during execution.
Click on the images to enlarge them

Original gripper

Diagram of the new gripper
